Séance 1: Compter les mots dans un fichier avec bash ! Problématique ???
1. Récupérer le contenu du fichier « la mort des amants » et le mettre dans le fichier amant.txt
2. Compter le nombre de mots qui apparaissent dans le fichier
La commande $ wc amant.txt sans option permet de compter le nombre de lignes, des mots et aussi des caractères d’un fichier. Dans cet exercice, on n’a besoin que l’information sur les nombres de mots donc la option -w me donner le résultat attendu.
3. Problématique
Compter des mots n’est pas un problème facile à résoudre. Le problème se pose qui est identifié comme un mot. Il est important qu’on s’assure l’exactitude de l’outil servant à compter. Pour clarifier le problème, je vais utiliser en même temps les autres outils de comptage. Le Microsoft Word dispose des moyens pour compter le nombre de mot. Mais il faut assurer que la langue choisie est bien la langue française. Au premier vu, il y a en tout 100 mots qui figurent dans ce poème.
Le rubrique review/Word Count nous permet de savoir les statistiques du text: le nombres de mots, le nombre de caractères avec ou sans espace et combien de paragraphes qu’on dispose.
On a perçu la différence de nombre de mots ici par rapport au logiciel Microsoft Word. Pages ne compte que 99 mots dans le fichier text. La question se pose comment on peut savoir quels sont les unités qui sont comptés comme « words » dans les deux logiciels. Je n’arrive pas à trouver la réponse pour le Microsoft Word.
Problème remarquable
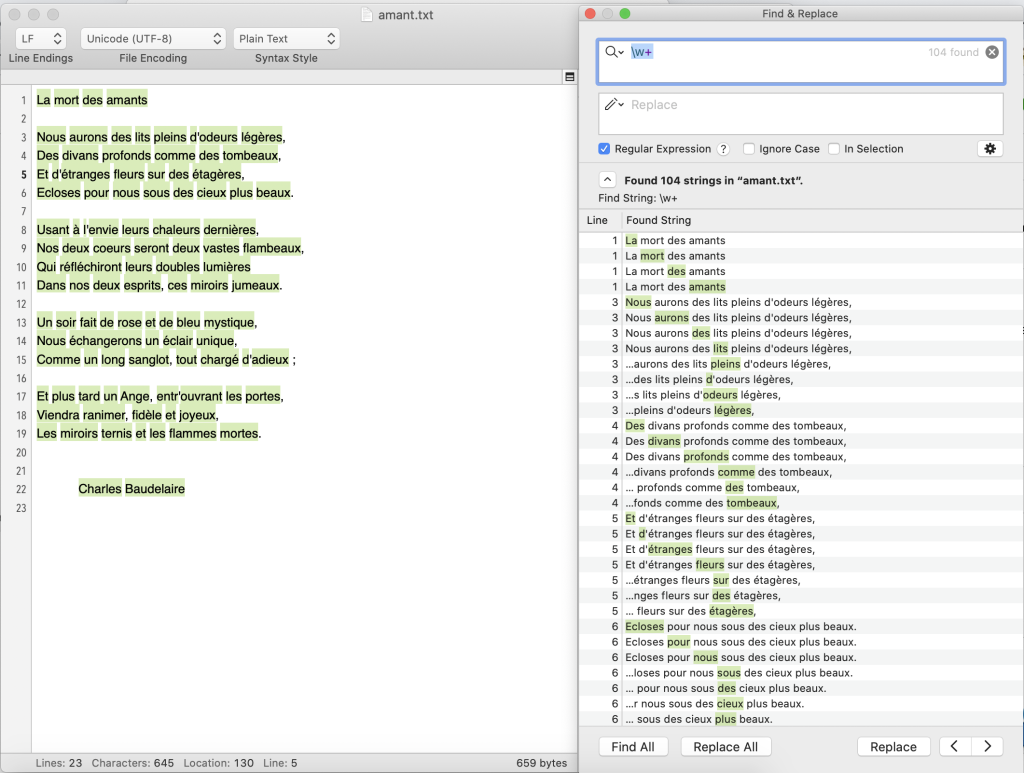
Dans un même logiciel, on peut apercevoir deux façon différente pour compter les unités dans un texte. Avec find et \W+ comme expression régulière, 104 strings ont été retrouvés. Avec bash, on peut compter les nombres de mots et ses occurrences dans le fichier en suivant cette instruction:
Le résultat attendu en suivant cette instruction:
$ egrep -o "(\w|')+" amant.txt | sort | uniq -c | sort -r
Avec cette instruction, d’adieux et entr‘ouvrant sont comptés comme un mot. Le nombre de mots avec cette requête est 99. Le résultat est égal à celui de cotEdit et de Pages et presque pour Words. En supprimant l’espace entre « d’adieux » et « ; », j’ai obtenu le même résultat.
Séance 2: Comment construire un tableau avec le fichier HTML
Dans le cadre de notre projet, on s’amuse à créer le tableau qui contient notre nom et notre sujet sous forme HTML.
Phase 1: Construire l’environnement de travail.
Créer du dossier “PROJET-MOT-SUR-LE-WEB » avec la commande:
Wget est un programme en ligne de commande non interactif de téléchargement de fichiers depuis le Web. Il nous permet de télécharger le fichier prepare-environnementprojet.sh depuis le site web de Tal. Et puis, pour l’excuter, on peut utiliser bash, sh ou chmod. Avant de lancer ce script on se place dans le répertoire du projet avec:
cd PROJET-MOT-SUR-LE-WEB
$ bash prepare-environnementprojet.sh
On peut vérifier si le fichier a été téléchargé avec find ou ls -l .
Phase 2: HTML
Exercice A: Écrire un script bash (que vous mettrez dans le dossier PROGRAMMES) permettant de générer dans le répertoire DUMP-TEXT un fichier txt contenant 2 lignes (sur la première, votre nom, sur la seconde, le mot choisi pour votre projet)
Les éditeurs de text sont servis à écrire des script bash. Pour le mac OS, on utilise CotEditor et Notepad ++ pour Ubuntu. On peut créer directement le fichier dans le terminal en suivant les instructions suivantes:
Créer le fichier script bashVoici notre script_nom.sh:Faire afficher le contenu du fichier nom_sujet.txt créé à partir de script_nom.sh
Exercice B: Ecrire un script bash (que vous mettrez dans le dossier PROGRAMMES) permettant de générer dans le répertoire TABLEAUX un fichier html contenant 1 tableaux avec 2 lignes (sur la première, votre nom, sur la seconde, le mot choisi pour votre projet)
On doit vérifier si on est dans le dossier PROGRAMMES avec $ pwd. Si c’est le cas, on va mettre la commande:
$ touch script_html.sh
Script bash pour générer un fichier html
Il faut qu’on exécute le fichier et on va vérifier qui est écrit dans le fichier index.html.
$ bash script_html.sh$
$ cd ../TABLEAUX$
$ cat index.html
Résultat obtenu
Séance 3: Tableaux URLS
Vu que le nombre de URLS recueille pour le mot retrouvaille ne suiffit pas pour l'analyse. J'ai décidé de changer le mot en métro
Résultat obtenu à partir de mon premier programme
Exercice (séance le 14/10/2020) : ajouter une colonne supplémentaire au tableau final et y insérer le numéro de la ligne lue.
Pendant le cours, on a vu comment lire les fichiers à partir de la commande en rajoutant les arguments dans le script. Pour exécuter le programme, il suffit de faire ce manif:
$1 et $2 nous permettent de ne pas mettre les noms de fichiers en code dur. C’est à dire qu'on peut les mettre dans la ligne de commande en suivant l'ordre prédéfini.
Pour créer le deuxième colonne, on rajoute soit <th>nombre_de_ligne</th> soit <td>nombre_de_ligne</td>. Pour la mise à jour de nombre de ligne, on va mettre un compteur i, i est initialisé à 0. Chaque fois, on ligne d'une ligne du fichier, le compte va être incrémenter de 1.
Exécuter du bash
J'ai obtenu le résultat comme prévu mais il existe un problème de codage en affichant le tableau. Le problème est dû au fait que j'ai enregistré le text: la mort des morts avec le logiciel TexEdit qui ne me permet pas d’enregistrer le text en UTF-8. On doit enregistrer des fichiers édités à la main donc il faut l’éditeur CotEditor sur MacOs.
Le résultat attendu
Séance 4: Recuperation des URLS
À l'aide de lynx -dump, on peut recueillir les urls de recherche sur le navigateur. Pour construire notre corpus, on a besoin de recueillir environ de 60 liens url de recherche du mot "métro" en français, vietnamien et en serbe. Pour chaque langue, il faut qu'on paramètre la langue de recherche en langue correspondant au mot.
Je tape "métro" sur la barre de recherche de google, je récupère le lien de recherche de la page 2 de google comme suit:
J'utilise lynx -dump pour récupérer 60 liens donc il faut créer un compteur comme condition d’arrêt de recherche.
$ count=0; while [ $count -le 300 ]; do lynx -dump "https://www.google.com/search?q=m%C3%A9tro&sxsrf=ALeKk01tohC7aWUDeCEBNhs5W1dyMa4sPg:1606344172719&ei=7N2-X_CtK8aSlwTf-pjACg&start=$count&sa=N&ved=2ahUKEwjw07Su4p7tAhVGyYUKHV89BqgQ8tMDegQIBxA8&biw=1440&bih=723" >> resgoogle.txt; count=$(($count + 20)); done
Le résultat obtenu
Vu que dans mon fichier, il y a beaucoup de bruits. Ce qu'on veut dans le corpus n'est que les liens URLs, donc on doit nettoyer le fichier avec l'aide de cut;
Séance 5: Représenter les urls sous forme du tableau
En classe, on a écrit un script qui permet de générer une page HTML avec des tableaux. Chaque tableau va contenir les urls dans un fichier txt dans le fichier passé en paramètres de la ligne de commande. Chaque ligne va contenir un URL. Mon tableau comprend 2 tableaux correspondant à 2 deux langues française et vietnamienne. Ce script a été enregistré dans le répertoire PROGRAMMES.
Voici le contenu du script
La commande qui me permet d’exécuter le programme (je suis dans le répertoire du projet):
La commande permet de trouver le fichier .sh dans le répertoire courant, prendre les urls dans le fichier URLS et se déplacer dans le répertoire TABLEAUX et générer le tableau des URL sous le nom: tableaux_URL.html. Pour vérifier si notre programme marche bien, je fais afficher le contenu du fichier tableaux_URL.html:
Dans le répertoire PAGES-ASPIREES, je trouve aussi les pages numérotés de nos urls.
Séance 6: Modifier le codage HTML pour établir un lien vers l'URL lue
On a remarqué que certains pages n'affichent pas correctement donc on a modifié notre script en rajoutant les conditions. Il faudrait aussi mettre en place une vérification de l'aspiration via CURL.
On est bien dans ce stade
Un code de retour est fourni par le shell après exécution d'une commande. Le code de retour est un entier positif ou nul, compris entre 0 et 255, indiquant si l'exécution de la commande s'est bien déroulée ou s'il y a eu un problème quelconque. Par convention, un code de retour égal à 0 signifie que la commande s'est exécutée correctement. Un code différent de 0 signifie une erreur syntaxique ou d'exécution. L’évaluation du code de retour est essentielle à l’exécution de structures de contrôle du shell telles que if et while.
Le paramètre spécial ? contient le code de retour de la dernière commande exécutée de manière séquentielle. Pour afficher le code de retour, on utilise la ligne de commande: echo $?. Si le résultat est égal à 0, c’est-à-dire que la page n’affiche pas correctement qui est du au fait que le curl ne marche pas bien. On utilise -w pour faire afficher les informations curl sur stdout après un transfert terminé. On veut récupérer la valeur du code HTTP : -w %{http_code}. On stock le code http récupéré dans une colonne du tableau avec echo. Si le code de retour est 200, on peut passer à l’étape suivant en rajoutant une condition.
Problème d'encodage.
Une condition imbriquée sera mise en place pour détecter l'encodage de nos URLS car les navigateurs sont codés par défaut en UTF-8. Pour ce fait, on va utiliser commande egrep -i charset pour récupérer l'encodage de nos urls. Si c'est bien le UTF-8, on va récupérer le contenu de la page. Si non, le tiret - va être rajouté dans le colonne du tableaux d'urls.
Une nouvelle variable a été rajoutée dans ce script pour stoker le motif passé en ligne de commande. On va rechercher tous les motifs dans le texte avec egrep -o -i. Une nouvelle colonne a aussi été rajoutée dans la tableau URLS pour stoker les occurrences du motif.
Seance 6 (suite): Extraction de bigrammes
Dans cette séance, on a utilisé le programme « minigrep-multilingue» qui est disponible sur http://www.tal.univ-paris3.fr/cours/minigrepmultilingue.htm. Le programme se lance avec perl. Il prend en argument l'encodage du fichier à filtrer, le fichier à filtrer, et le fichier motif_regrepx.txt (représentation des motifs sous forme regex). On recherche le contexte autour du motif soit avec egrep soit avec minigrep. Pour le "egrep", il faut qu'on rajoute des options pour faire afficher aussi le contexte suivant et après le mot choisi.
egrep -C 2 -i "$motif" ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt > ./CONTEXTES/utf8_"$compteur_tableau-$compteur".txt;
# 2. donner à voir ces contextes au format HTML
perl ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/minigrepmultilingue.pl "UTF-8" ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/motif-2020.txt ;
# attention il faut "sauvegarder" le résultat
mv resultat-extraction.html ./CONTEXTES/"$compteur_tableau-$compteur".html;
Après l’exécution du programme, il faut trouver dans le répertoire CONTEXT les fichiers html et txt mais ce n'est pas mon cas. Il peut être causer par le fait que j'ai pas bien installé minigrep (mini grep permet de représenter les contextes de façon plus clair).
Pour créer des bigrammes, on utlise tr- pour supprimer les lignes vides , et mettre chaque mot sur une ligne, puis le tail et paste pour créer des bigrammes. Exemples de mes bigrammes en vietnamien.
Script final et analyse
Pour permettre de changer la direction, on va rajouter les options pour la commande curl.
Pour les urls avec l'encodage non UTF-8, on va convertir en UTF avec iconv.
# via la commande lynx : ici on choisit de dumper la page aspirée...
lynx -dump -nolist -assume_charset="UTF-8" -display_charset="UTF-8" ./PAGES-ASPIREES/"$compteur_tableau-$compteur".html > ./DUMPTEXT/utf8_"$compteur_tableau-$compteur".txt;
iconv -f $codageURL -t UTF-8 ./DUMP-TEXT/"$compteur_tableau-$compteur"-dump.txt > ./DUMP-TEXT/"$compteur_tableau-$compteur"-dump-utf8.txt;
Après l’exécution de ce script, il faut que tous les codages non-UTF-8 doit être converti en UTF-8 mais il me reste encore quelques pages qui codent en ISO latin 1.
Préparation des corpus pour l'analyse
On doit concatener les fichiers de français et l'autre pour le vietnamien dans le répertorie CONTEXTES dans un fichier et ceux dans DUMPS dans un fichier. Pour les fichier en français , le nom du fichier se commence avec 1 et se termine par utf8.txt donc je fais:
for file in `ls 1-*.txt` ; do echo "<partie=$file>" >> CORPUS1.txt; cat $file >> CORPUS1.txt ; echo "</partie>" >> CORPUS1.txt; done;
Pour le vietnamien:
for file in `ls 2-*.txt` ; do echo "<partie=$file>" >> CORPUS2.txt; cat $file >> CORPUS2.txt ; echo "</partie>" >> CORPUS2.txt; done;
Dans le répertoire CONTEXTE, je fais for file in `ls utf8_2-*.txt` ; do echo "<partie=$file>" >> CORPUS2.txt; cat $file >> CORPUS2.txt ; echo "</partie>" >> CORPUS2.txt; done;
Chargement des corpus pour l'analyse
il me semble que la page s'affiche pas correctement. le contexte du mot metro